
Claude Sonnet 4.5: Slow and Steady Wins the Race

Claude Sonnet 4.5 launched 24 hours ago, but we already have solid indication of where its substantial agentic and coding upgrades come from. Turns out, slow and steady really does win the race.
One of the authors from SWE-bench (a coding benchmark for large language models) shared a few graphs showing how different models perform using the “bash-only” minimal agent setup. This setup gives all models identical tooling, isolating what comes from the model itself versus the surrounding infrastructure. And the data reveals something fascinating about how Sonnet 4.5 approaches problem-solving.
The Performance Story
First, the headline numbers. On SWE-bench bash-only (the minimal agent setup), Sonnet 4.5 achieves 70.6%, outperforming GPT-5, and even the larger Opus 4. By the way, these bash-only results differ from the standard SWE-bench Verified scores you might have seen elsewhere.

The Cost Paradox
Here’s where things get interesting. Opus 4 is 5x more expensive per token than Sonnet 4.5. Yet on the full SWE-bench run, it only costs about 2x as much: $566 versus $279. Compared to its direct predecessor, 4.5 costs 50% more on SWE-bench, while having the same pricing over the API.
What’s going on?
The Step Pattern
The SWE-bench author shared another chart, showing how many steps (think ‘edits’) each LLM needed to solve the coding problems.
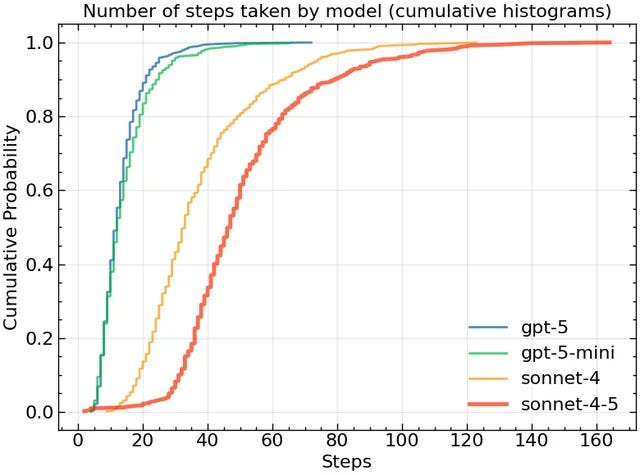
The chart shows how likely it is for each model to solve a task in a certain number of steps. On average (y=0.5), Sonnet 4.5 needed 47 steps to solve a problem compared to 32 steps of its predecessor. That’s roughly 50% more and explains the cost gap from above. Sonnet 4.5 appears to employ a fundamentally different problem-solving strategy:
Small, iterative refinements over comprehensive rewrites.
Instead of attempting to solve a problem in a couple of large code changes Sonnet 4.5 makes smaller, targeted modifications across many more iterations. It’s the difference between a developer doing a complete file rewrite versus making careful, incremental changes with frequent testing.
GPT-5 appears to take a different approach completely. It finishes each assignment in a quarter of edits compared to Sonnet 4.5. While not matching Claude’s performance, it appears to act more token efficient, arguably coming from a stronger sense of planning and reasoning I want to talk about in another article.
Why This Works
Code has a unique property that makes this strategy viable: it’s testable at every step. Unlike writing prose or generating images, code can be validated incrementally. Each small change can be:
Syntactically checked
Run against tests
Evaluated for correctness
Refined if needed
This makes iteration less risky and more valuable. A wrong turn in step 5 doesn’t waste steps 1-4; you simply adjust and continue, knowing exactly what triggered the problem.
Anthropic mentioned in their model announcement that Sonnet 4.5 has shown to work for up to 30 hours completely autonomously. Earlier models couldn’t maintain focus on a single task for this long. But extended operation time enables a different approach: patient, systematic refinement over many iterations rather than attempting to nail it in a few shots.
Looking Forward
If this approach proves consistently superior, we might see other models adopt similar iterative strategies. Or we might see a bifurcation: “fast solvers” optimized for quick, efficient answers, and “careful iterators” optimized for maximum accuracy through systematic refinement.
For now, the data suggests something important: the path to better AI (coding) agents might not be about making models that can solve problems in fewer steps. It might be about making models that know when to take more steps—and building the infrastructure that makes those extra steps economically and practically viable.
Sonnet 4.5’s success is about being more patient, more thorough, and more willing to iterate. In the race to build better agents, that might be exactly what wins.